There really are some incredible bloggers out there. Despite my recent 5 day series on Continuous Integration, I typically struggle to blog more frequently than once a week. Yet these guys have committed to a whole month of blogging on a single topic and the quality of the blogs isn't diluted at all giving a real "Deep Dive" into a topic.
So here are some of the "A Day" series that i've dipped into recently - I would bet that there will be more to be added. Credit to the guys and I doff my hat to you.
-- A DMV a day
http://sqlserverperformance.wordpress.com/2010/04/
-- XE a day
http://sqlblog.com/blogs/jonathan_kehayias/archive/2010/12/01/a-xevent-a-day-31-days-of-extended-events.aspx
-- A SQL Myth a day
http://www.sqlskills.com/BLOGS/PAUL/post/A-SQL-Server-DBA-myth-a-day-%28130%29-in-flight-transactions-continue-after-a-failover.aspx
-- SSIS a day
http://www.jasonstrate.com/2011/01/31-days-of-ssis-raw-files-are-awesome-131/
Thursday, 27 October 2011
Friday, 21 October 2011
Admin: Generate Restore Scripts
In order to speed up the recovery process of database (and to give the unintentional DBAs in my organsiation) a helping hand, I recently started experimenting with generating restore scripts for our production databases.
As is my wont, my technology preference was again Powershell (although it did make use of T-SQL too) as looping through databases on a server and writing to file are all pretty trivial.
I wrote a simple TVF to generate the restore script for a particular database, based upon the system tables in MSDB and based closely on the script found on MSSQLTIPS.
This was the sort of thing I needed and then all I was left to do was write a powershell script to execute this command for each database and persist the results to a file:
The key thing to note here is that I've created the TVF in a central database GlobalDB which I use for admin/logging tasks on the server. This saves me from having to keep a copy of the script in each database (although I could achieve the same behaviour by installing it into the Master database or MSDB database).
Also, there is reference to a hack which I talked about in a previous post.
The final part of the jigsaw was being able to schedule this to run every time there was a backup so it would pickup the latest backup sets. SQL Agent in SQL2008 has a Powershell step but this will actually execute code held within the SQL job. For me, I want to be able to manage my powershell scripts independantly (keeping them under source control etc) so really, I just want to point SQLAgent at a script and execute it. Turns out this can be achieved using the CmdExec step:
powershell "& D:\SQLAdmin\CreateDBRestoreCommands.ps1"
The main downside to this is the permissions as running this Job Step type will mean the job runs under the context of the SQL Agent and, unless I set up a proxy, I will need to grant some database permissions (SELECT on the TVF) to the SQL Agent login account. As a quick fix, I granted SELECT permissions on the TVF to the Public role and off we went.
As is my wont, my technology preference was again Powershell (although it did make use of T-SQL too) as looping through databases on a server and writing to file are all pretty trivial.
I wrote a simple TVF to generate the restore script for a particular database, based upon the system tables in MSDB and based closely on the script found on MSSQLTIPS.
CREATE FUNCTION [dbo].[tvf_GetRestoreCommands](@DatabaseName SYSNAME)RETURNS
@AllCommands TABLE (
[backup_set_id] INT NULL,
[Command] NVARCHAR (MAX) NULL
)AS
BEGIN
DECLARE @backupStartDate DATETIME
DECLARE @backup_set_id_start INT
DECLARE @backup_set_id_end INT
DECLARE @IncludeMoveClause BIT = 1
DECLARE @MoveClause NVARCHAR(255) = ''
-- get the most recent full backup
SELECT @backup_set_id_start = MAX(backup_set_id)
FROM msdb.dbo.backupset
WHERE database_name = @databaseName
AND TYPE = 'D'
SELECT @backup_set_id_end = MIN(backup_set_id)
FROM msdb.dbo.backupset
WHERE database_name = @databaseName AND TYPE = 'D'
AND backup_set_id > @backup_set_id_start
IF @backup_set_id_end IS NULL SET @backup_set_id_end = 999999999
-- do you want to include the move clause in case of having to go to a different server
IF @IncludeMoveClause = 1
SELECT @MoveClause = COALESCE(@MoveClause + ',','') + ' MOVE ' + QUOTENAME(name,'''') + ' TO ' + QUOTENAME(physical_name, '''')
FROM sys.master_files
WHERE database_id = DB_ID(@databaseName);
INSERT INTO @AllCommands
SELECT backup_set_id, 'RESTORE DATABASE ' + @databaseName + ' FROM DISK = '''
+ mf.physical_device_name + ''' WITH NORECOVERY, STATS = 5 ' + @MoveClause
FROM msdb.dbo.backupset b
INNER JOIN msdb.dbo.backupmediafamily mf
ON b.media_set_id = mf.media_set_id
WHERE b.database_name = @databaseName
AND b.backup_set_id = @backup_set_id_start
UNION
SELECT backup_set_id, 'RESTORE LOG ' + @databaseName + ' FROM DISK = '''
+ mf.physical_device_name + ''' WITH NORECOVERY'
FROM msdb.dbo.backupset b,
msdb.dbo.backupmediafamily mf
WHERE b.media_set_id = mf.media_set_id
AND b.database_name = @databaseName
AND b.backup_set_id >= @backup_set_id_start
AND b.backup_set_id < @backup_set_id_end
AND b.TYPE = 'L'
UNION
SELECT 999999999 AS backup_set_id, 'RESTORE DATABASE ' + @databaseName + ' WITH RECOVERY'
ORDER BY backup_set_id
RETURN
END
This was the sort of thing I needed and then all I was left to do was write a powershell script to execute this command for each database and persist the results to a file:
# Load the SQL Management Objects assembly (Pipe out-null supresses output)[System.Reflection.Assembly]::LoadWithPartialName("Microsoft.SqlServer.SMO") | out-nulladd-pssnapin SqlServerCmdletSnapin100
$server = hostname;$backupdir = "E:\SQLBackup\Scripts\Restore\";$sql = new-object "Microsoft.SqlServer.Management.SMO.Server" $server;# Get databases on our server
$databases = $sql.Databases | Where-object {$_.IsSystemObject -eq $false};# generate the restore commandforeach ($db in $databases){
$filePath = $backupdir + 'Restore_' + $db.name + '.sql'
$dbname = $db.Name
$sqlresults = Invoke-Sqlcmd -Query "SELECT [Command] FROM GlobalDB.dbo.tvf_GetRestoreCommands('$dbname')" -ServerInstance $sql_server
# nasty hack here to force the output to fit in. Hope my restore command isn't > 3000 chars!
$sqlresults | out-file -filepath $filepath -width 3000
}
The key thing to note here is that I've created the TVF in a central database GlobalDB which I use for admin/logging tasks on the server. This saves me from having to keep a copy of the script in each database (although I could achieve the same behaviour by installing it into the Master database or MSDB database).
Also, there is reference to a hack which I talked about in a previous post.
The final part of the jigsaw was being able to schedule this to run every time there was a backup so it would pickup the latest backup sets. SQL Agent in SQL2008 has a Powershell step but this will actually execute code held within the SQL job. For me, I want to be able to manage my powershell scripts independantly (keeping them under source control etc) so really, I just want to point SQLAgent at a script and execute it. Turns out this can be achieved using the CmdExec step:
powershell "& D:\SQLAdmin\CreateDBRestoreCommands.ps1"
The main downside to this is the permissions as running this Job Step type will mean the job runs under the context of the SQL Agent and, unless I set up a proxy, I will need to grant some database permissions (SELECT on the TVF) to the SQL Agent login account. As a quick fix, I granted SELECT permissions on the TVF to the Public role and off we went.
Thursday, 13 October 2011
Denali SSIS: Loop through a list of servers
Its been tough to get any time recently to play with Denali, so I thought i'd put together a quick tutorial on SSIS using Denali to give people a tiny flavour of what it looks like. I intend (time permitting) to use this tutorial in the future to extend the package to show off a few of the new features of Denali.
Note: this task can be achieved in previous versions of SSIS with minimal changes.
The aim of this package is a simple one: to iterate over a list of Servers and execute a SQL task against each one. I've also thrown in a Script task too for good measure.
Setup
First up, we'll set up the test data in Management Studio (look at that cool Denali syntax colouring!):

Then we move into Visual Studio to start our package:
Although I've not configured the Tasks yet, you can immediately get a feel for what the purpose of this package is going to be. As you might expect, there is improved "kerb appeal" from MS in this release with smoother graphics and features such as the magnifier which allow you to make your design more readable.

Configuration
1) T-SQL - Get Servers:
The Execute T-SQL dialog box is straight forward enough to configure. The main thing to note on the General tab is that you need to set the ResultSet appropriately to Full result set.

On the Result Set tab, you need to set your Result to a variable of type Object. If you haven't already created your variable, you can create one from this dialog box.

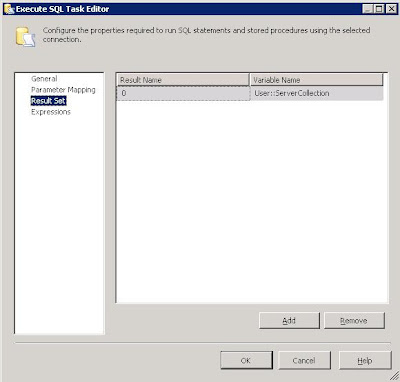
2) For Each Loop - Servers
We just need to choose the Foreach ADO Enumerator and select the object source variable to be that you populated in the previous task. Simple.

Click onto the Variable Mappings and here is where you'll pull out the relevant details from your object. In our case, we just need to grab the ServerName and populate a simple string variable to use in the tasks within the container. You need to map these variables by Zero based Index and we're only interested in the first column, hence Index 0.

3) T-SQL - Get Version
Another T-SQL task here, but the clever part is that we need the connection to be dynamic. In other words, for each server in our collection, we need to connect to that server and get its version.
First, we add an extra connection using the Connection Manager (Note, I also change my connection name to show that its dynamic - i've called it DynamicSQLConn)

We can make the connection dynamic by changing the ConnectionString property on each iteration of the loop. To do this, we dive into the Properties window and click on Expressions:

We just then set the ConnectionString property to something like the following:
"Data Source=" + @[User::ServerName] + ";Initial Catalog=master;Provider=SQLNCLI11.1;Integrated Security=SSPI;Auto Translate=False;"

Now we can just use this connection string in our T-SQL task. I've chosen to return the results of @@VERSION. Its a single column, single row result set so i've chosen the Single Row result set.

Now we just need to configure the Result Set by sending the output to another string variable

4) Script Task - Show Version
Now typically, you'd want to do something more appropriate than just showing your results via a Message Box but this is exactly what i'm going to do. If nothing else, it illustrates the use of the Script Task.
We just open up the task and we need to pass in the variables we wish to use. You can type them in, or just use the select dialog box thats provided. As we're only displaying, they just need to be ReadOnlyVariables.

When you click Edit Script, you get a new instance of Visual Studio open up to add your code. We only need to modify the Main method:

And thats it!!
Execution
You can test and execute the package through Visual Studio and see even more of that "Kerb Appeal" that I talked about earlier. Gone are the garish colours associated with previous versions of SSIS and they've been replaced by more subtle and sexy icons:

Hopefully this has been helpful in giving a quick glance at the look and feel of Denali SSIS while also showing how you can SSIS to loop over a dataset.
Specifically the main points to take away are:
1) For Each Loop Container with an ADO Enumerator, using the Object variable and accessing properties of the object
2) T-SQL Task - using a dynamic connection with Expressions, using different Result Sets and populating variables from result sets
3) Script Task - passing in variables and writing a simple task.
Note: this task can be achieved in previous versions of SSIS with minimal changes.
The aim of this package is a simple one: to iterate over a list of Servers and execute a SQL task against each one. I've also thrown in a Script task too for good measure.
Setup
First up, we'll set up the test data in Management Studio (look at that cool Denali syntax colouring!):

Then we move into Visual Studio to start our package:
Although I've not configured the Tasks yet, you can immediately get a feel for what the purpose of this package is going to be. As you might expect, there is improved "kerb appeal" from MS in this release with smoother graphics and features such as the magnifier which allow you to make your design more readable.
Configuration
1) T-SQL - Get Servers:
The Execute T-SQL dialog box is straight forward enough to configure. The main thing to note on the General tab is that you need to set the ResultSet appropriately to Full result set.

On the Result Set tab, you need to set your Result to a variable of type Object. If you haven't already created your variable, you can create one from this dialog box.


2) For Each Loop - Servers
We just need to choose the Foreach ADO Enumerator and select the object source variable to be that you populated in the previous task. Simple.

Click onto the Variable Mappings and here is where you'll pull out the relevant details from your object. In our case, we just need to grab the ServerName and populate a simple string variable to use in the tasks within the container. You need to map these variables by Zero based Index and we're only interested in the first column, hence Index 0.

3) T-SQL - Get Version
Another T-SQL task here, but the clever part is that we need the connection to be dynamic. In other words, for each server in our collection, we need to connect to that server and get its version.
First, we add an extra connection using the Connection Manager (Note, I also change my connection name to show that its dynamic - i've called it DynamicSQLConn)

We can make the connection dynamic by changing the ConnectionString property on each iteration of the loop. To do this, we dive into the Properties window and click on Expressions:

We just then set the ConnectionString property to something like the following:
"Data Source=" + @[User::ServerName] + ";Initial Catalog=master;Provider=SQLNCLI11.1;Integrated Security=SSPI;Auto Translate=False;"

Now we can just use this connection string in our T-SQL task. I've chosen to return the results of @@VERSION. Its a single column, single row result set so i've chosen the Single Row result set.
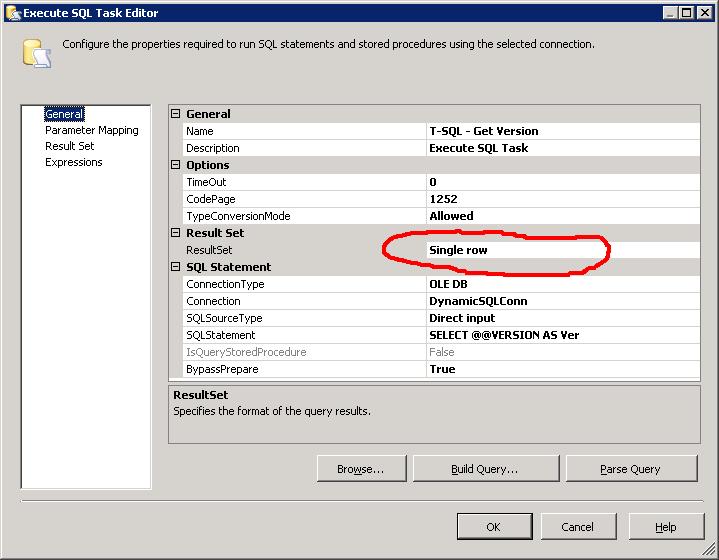
Now we just need to configure the Result Set by sending the output to another string variable

4) Script Task - Show Version
Now typically, you'd want to do something more appropriate than just showing your results via a Message Box but this is exactly what i'm going to do. If nothing else, it illustrates the use of the Script Task.
We just open up the task and we need to pass in the variables we wish to use. You can type them in, or just use the select dialog box thats provided. As we're only displaying, they just need to be ReadOnlyVariables.

When you click Edit Script, you get a new instance of Visual Studio open up to add your code. We only need to modify the Main method:
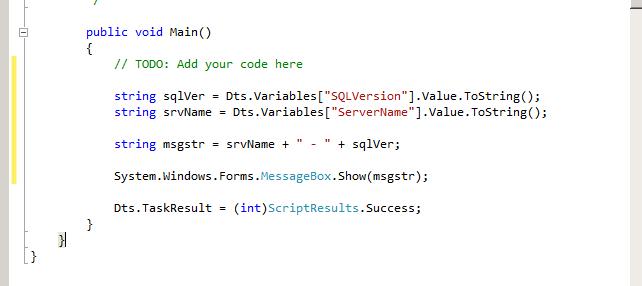
And thats it!!
Execution
You can test and execute the package through Visual Studio and see even more of that "Kerb Appeal" that I talked about earlier. Gone are the garish colours associated with previous versions of SSIS and they've been replaced by more subtle and sexy icons:

Hopefully this has been helpful in giving a quick glance at the look and feel of Denali SSIS while also showing how you can SSIS to loop over a dataset.
Specifically the main points to take away are:
1) For Each Loop Container with an ADO Enumerator, using the Object variable and accessing properties of the object
2) T-SQL Task - using a dynamic connection with Expressions, using different Result Sets and populating variables from result sets
3) Script Task - passing in variables and writing a simple task.
Tuesday, 4 October 2011
T-SQL: Helping the optimiser can hinder

Essentially, this post is about reading the results of SHOWPLAN_TEXT, being aware of the different physical join operators and also how the optimiser can be influenced (poorly) by a bad WHERE clause.
I have the following query on a view which abstracts the 4 tables joined:
SELECT *, CAST(Val AS NUMERIC(22,16)) FROM DDL.vwData The tables behind the view aren't really that important, as I just want to concentrate on the plans generated but basically, there is a lookup table for RateID and then a maindata table which joins to this table (via other intermediate tables). The key thing to note in the query though is the CAST - sometimes the column Val (from maindata) has a value which can't be converted - indeed running this query as is gives the error:
Msg 8115, Level 16, State 8, Line 2
Arithmetic overflow error converting numeric to data type numeric.
I know the data for RateID does have Vals which are CASTable to the decimal precision/scope and changing the query to only return those records where RateID = 1, returns a result set without errors:
SELECT *, CAST(Val AS NUMERIC(22,16)) FROM DDL.vwRateData WHERE RateId = 1 However, if I "improve" the query to filter out these records further to only return data from the last month using a non-sargable clause, i get that pesky overflow error again:
SELECT *, CAST(Val AS NUMERIC(22,16)) FROM DDL.vwRateData WHERE RateId = 1 AND DATEDIFF(D,GETDATE(),[Date])< 365
So whats different? First glance suggests something is wrong because if the whole dataset for RateId=1 returns without error, then choosing a further subset of this data should also work.
I delved into the query plans to find out and the clue was there:
The Good query generated a plan that was using a Nested Loops inner join. In a nutshell, the first thing this query does is filter out the correct rows from the lookup table (RateID = 1) and then iterates through the main table where there is a match on that RateId. In other words, it doesn't matter whether or not the Val column for other RateIDs is CASTable as this plan only touches RateID = 1.


The different types of JOINs (both logical and physical) are explained really well in this article but the "takeaway" from this post is that you need to be careful with your query construction as the optimiser may choose a plan that can influence both performance and even robustness. Logic may tell you that adding extra filtering criteria will help the optimiser choose a more efficient plan, but in this example it has chosen a plan that has caused the query to fail.
Subscribe to:
Posts (Atom)