Its been tough to get any time recently to play with
Denali, so I thought i'd put together a quick tutorial on SSIS using Denali to give people a tiny flavour of what it looks like. I intend (time permitting) to use this tutorial in the future to extend the package to show off a few of the new features of Denali.
Note: this task can be achieved in previous versions of SSIS with minimal changes.
The aim of this package is a simple one: to iterate over a list of Servers and execute a SQL task against each one. I've also thrown in a Script task too for good measure.
Setup
First up, we'll set up the test data in Management Studio (look at that cool Denali syntax colouring!):
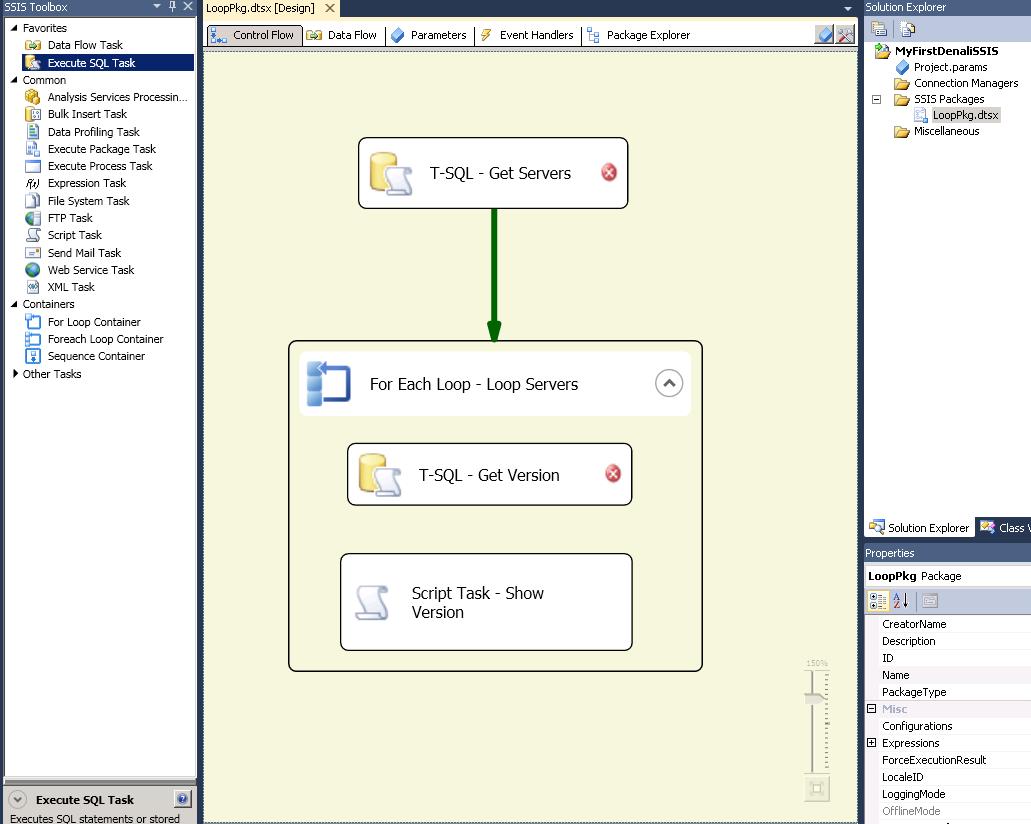
Then we move into Visual Studio to start our package:
Although I've not configured the Tasks yet, you can immediately get a feel for what the purpose of this package is going to be. As you might expect, there is improved "kerb appeal" from MS in this release with smoother graphics and features such as the magnifier which allow you to make your design more readable.
Configuration
1) T-SQL - Get Servers:
The Execute T-SQL dialog box is straight forward enough to configure. The main thing to note on the General tab is that you need to set the ResultSet appropriately to
Full result set.
On the Result Set tab, you need to set your Result to a variable of type Object. If you haven't already created your variable, you can create one from this dialog box.
2) For Each Loop - Servers
We just need to choose the Foreach ADO Enumerator and select the object source variable to be that you populated in the previous task. Simple.
Click onto the Variable Mappings and here is where you'll pull out the relevant details from your object. In our case, we just need to grab the ServerName and populate a simple string variable to use in the tasks within the container. You need to map these variables by Zero based Index and we're only interested in the first column, hence Index 0.
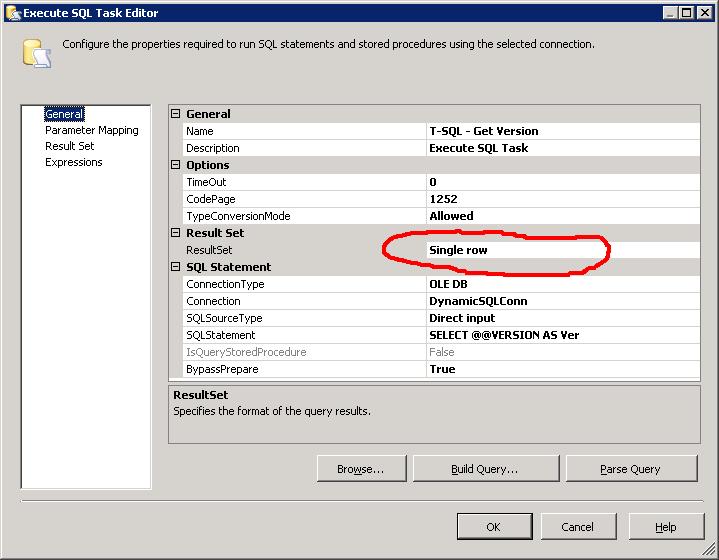
3) T-SQL - Get Version
Another T-SQL task here, but the clever part is that we need the connection to be dynamic. In other words, for each server in our collection, we need to connect to that server and get its version.
First, we add an extra connection using the Connection Manager (Note, I also change my connection name to show that its dynamic - i've called it
DynamicSQLConn)
We can make the connection dynamic by changing the ConnectionString property on each iteration of the loop. To do this, we dive into the Properties window and click on Expressions:
We just then set the ConnectionString property to something like the following:
"Data Source=" + @[User::ServerName] + ";Initial Catalog=master;Provider=SQLNCLI11.1;Integrated Security=SSPI;Auto Translate=False;"
Now we can just use this connection string in our T-SQL task. I've chosen to return the results of @@VERSION. Its a single column, single row result set so i've chosen the Single Row result set.
Now we just need to configure the Result Set by sending the output to another string variable
4) Script Task - Show Version
Now typically, you'd want to do something more appropriate than just showing your results via a Message Box but this is exactly what i'm going to do. If nothing else, it illustrates the use of the Script Task.
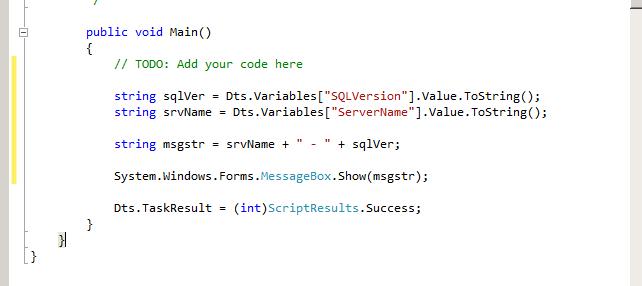
We just open up the task and we need to pass in the variables we wish to use. You can type them in, or just use the select dialog box thats provided. As we're only displaying, they just need to be ReadOnlyVariables.
When you click Edit Script, you get a new instance of Visual Studio open up to add your code. We only need to modify the
Main method:
And thats it!!
Execution
You can test and execute the package through Visual Studio and see even more of that "Kerb Appeal" that I talked about earlier. Gone are the garish colours associated with previous versions of SSIS and they've been replaced by more subtle and sexy icons:
Hopefully this has been helpful in giving a quick glance at the look and feel of Denali SSIS while also showing how you can SSIS to loop over a dataset.
Specifically the main points to take away are:
1) For Each Loop Container with an ADO Enumerator, using the Object variable and accessing properties of the object
2) T-SQL Task - using a dynamic connection with Expressions, using different Result Sets and populating variables from result sets
3) Script Task - passing in variables and writing a simple task.