I've been doing a little web development work recently with MVC and have come across a (very) minor issue when deploying this to my test server.
Essentially, I've deployed to the application to the server but when I access it via the IP Address, I get prompted for my windows credentials. However, when accessing it via server name I am not prompted and I get the (much better) user experience of auto authentication.
It appears that the issue is not with IIS or my MVC app but with my browser and the way it handles different URL patterns. When accessing it via server name (eg HTTP//Servername/App) the browser "knows" the site is internal so automatically authenticates whereas the IP address (HTTP//1.1.1.1/App) could be external and so throws the prompt.
Its explained here in David Wang's blog.
Monday, 17 September 2012
T-SQL: Allow low privileged user to Truncate table
The problem with TRUNCATE is that it is a DDL statement rather than the regulation DELETE statement which is DML. As such, its not captured by using the db_datewriter database role and so on the face of it, you're left with two options:
1) Add the user to db_ddladmin role (or db_owner)
2) Grant ALTER table permissions to the table(s) in question
I'm not really a fan of either of these approaches as the first gives far too much control to the user and I try to avoid giving object level permissions if possible.
An alternative is to make use of the EXECUTE AS clause and wrap your TRUNCATE statement within a stored procedure and grant permissions on that instead.
Msg 1088, LEVEL 16, State 7, Line 1
1) Add the user to db_ddladmin role (or db_owner)
2) Grant ALTER table permissions to the table(s) in question
I'm not really a fan of either of these approaches as the first gives far too much control to the user and I try to avoid giving object level permissions if possible.
An alternative is to make use of the EXECUTE AS clause and wrap your TRUNCATE statement within a stored procedure and grant permissions on that instead.
-- create a test database CREATE DATABASE TruncateTest
GOUSE TruncateTest
GO-- create a low privilege user to test withCREATE USER NoRights WITHOUT LOGIN
GO-- create a table to test againstCREATE TABLE dbo.TestData (Id INT IDENTITY(1,1))GO-- add some dummy dataINSERT INTO dbo.TestData DEFAULT VALUESGO 20-- check the data is okSELECT COUNT(*) FROM dbo.TestData
GO-- impersonate the test userEXECUTE AS USER = 'NoRights'GO-- try to issue the truncate commandTRUNCATE TABLE dbo.TestData
GOMsg 1088, LEVEL 16, State 7, Line 1
Cannot find the object "TestData" because it does not exist or you do not have permissions.-- switch back to my superuserREVERT
GO-- create a wrapper procedure to truncate the tableCREATE PROCEDURE dbo.TruncateTestDataAS
TRUNCATE TABLE dbo.TestData
GO-- grant execute to the test userGRANT EXECUTE ON dbo.TruncateTestData TO NoRights
GO-- impersonate the test userEXECUTE AS USER = 'NoRights'GO-- execute the procedureEXEC dbo.TruncateTestData
GOMsg 1088, Level 16, State 7, Procedure TruncateTestData, Line 4Cannot find the object "TestData" because it does not exist or you do not have permissions.-- switch back to my superuserREVERT
GO-- modify the procedure to execute in the context of the owner (dbo)ALTER PROCEDURE dbo.TruncateTestDataWITH EXECUTE AS OWNERAS
TRUNCATE TABLE dbo.TestData
GO-- impersonate the test userEXECUTE AS USER = 'NoRights'GO-- execute the procedureEXEC dbo.TruncateTestData
GO-- switch back to the superuserREVERT
GO-- check the dataSELECT COUNT(*) FROM dbo.TestData
GO-- tidy upDROP DATABASE TruncateTest
GO
Thursday, 26 July 2012
SSMS: Help prevent the "oh ****" moment
Its funny how sometimes you think of something which would be great idea and then the solution falls into your lap. This very thing happened to me the other day after an "oh ****" moment when I executed a query on a production server rather than the test server. Unfortunately, there weren't any fail safes in place (eg restricted privileges) so the query ran successfully and promptly updated a stack of live data. Fortunately, the database in question was not being used and so there was no impact on users but this could so easily have not been the case.
I'm sure I haven't been the only one bitten by this, and it occurred to me that this is far too easy to do. When in fire-fighting mode it can often be the case that I'm flicking between windows with many connection windows open at one time and even the most diligent person can get caught out running a query on the wrong database. When its just a SELECT statement or you issue a query that is in the wrong database thats no big deal but if its a DML (or worse a DDL!!) statement then things can get pretty ugly quickly.
 I won't go into details of all the cool tools that are mentioned in the post, but the SSMS Tools Pack has (amongst other things) functionality that replicates what I was hoping for. You can essentially configure a colour strip for a database server which is a simple visual aid to help you recognise when you in "the danger zone".
I won't go into details of all the cool tools that are mentioned in the post, but the SSMS Tools Pack has (amongst other things) functionality that replicates what I was hoping for. You can essentially configure a colour strip for a database server which is a simple visual aid to help you recognise when you in "the danger zone".
Even better than this is the fact that you can configure a template for a New Query connection which I tweaked to try and remind the user to be aware of the colour. This means that every time I hit the New Query button the query opens with the text to remind the user to check the server with arrows pointing to the colour bar.

I'm sure I haven't been the only one bitten by this, and it occurred to me that this is far too easy to do. When in fire-fighting mode it can often be the case that I'm flicking between windows with many connection windows open at one time and even the most diligent person can get caught out running a query on the wrong database. When its just a SELECT statement or you issue a query that is in the wrong database thats no big deal but if its a DML (or worse a DDL!!) statement then things can get pretty ugly quickly.
What would have been really helpful for me was an obvious indicator showing which server I was on - probably a different coloured query window (red for Prod please!!) for each database server. And then, on my daily trawl through my twitter timeline I came across this tweet:
RT @tsqlninja: [Blogged] Tools of the trade. My list of top sql server tools tsqlninja.wordpress.com featuring @redgate @MladenPrajdic...
— SQLServerCentral (@SQLServerCentrl) July 25, 2012
Even better than this is the fact that you can configure a template for a New Query connection which I tweaked to try and remind the user to be aware of the colour. This means that every time I hit the New Query button the query opens with the text to remind the user to check the server with arrows pointing to the colour bar.

This obviously isn't a full proof solution and is no substitute for having more stringent measures in place to prevent issues such as issuing a delete statement on a production server in error. However, it is simple and effective and is another tool you can have in your armoury to help prevent downtime or dataloss. Every little helps!
Thursday, 19 July 2012
Powershell: String concatenation with underscore confusion
In putting together a simple powershell script to download a file and store it on a filesystem, I came across some strangeness with the user of Underscore (_) when concatenation variables. Essentially, I wanted to create a filename based upon 2 powershell variables, separated by an underscore.
I wanted my filename to be:
I wanted my filename to be:
Richard_Brown.txt
And my powershell read something like:
$File = "C:\$FirstName_$LastName"
Interestingly, when run in my script the output of $File would be
C:\Brown.txt
I was suspicious of the underscore and sure enough this was the causing the issue. I stumbled upon this thread on Stackoverflow which explains the issue as the underscore is a valid character in identifiers so its looking for a variable named $FirstName_.
There are 2 workarounds for this:
1) $File = "C:\$FirstName`_$LastName"
2) $File = "C:\${FirstName}_$LastName"
Tuesday, 17 July 2012
T-SQL Tuesday #32 - A Day In The Life
T-SQL Tuesday has been a little off my radar for the last few months (as has all blogging activity!), so I was delighted when Twitter reminded me that it was that time of the month. Even better, the topic chosen by Erin Stellato (Blog | Twitter) was a great one that I felt I could really engage with.
 So here we go. For the record, my job title is Database Administrator.
So here we go. For the record, my job title is Database Administrator.
The task as laid out in the invitation suggested to talk through your day on the 11th or 12th July which just so happened to be the day I resigned from my current role. Writing down a handover list was an interesting task in itself as it gave me the opportunity to put down in words what the key parts of my job were and what skills gap would be left. I have to say, I was surprised (and pleased) that the number of tasks on the list that required significant handover to another collegue were minimal as I have been very diligent in ensuring that I was not a Single Point of Failure in my organisation. As such, I have written plenty of documentation and made extensive use of Source Control and Task Tracking systems to ensure that even if people do not know what I've done, there is a paper trail to explain it.
What was apparent was the varying skills I employ in my day to day, many of which are not even related directly to SQL Server. Much of my day is spent in project meetings, planning or analysing roadmaps and although the applications typically have a database backend, its not the focus of my attention. I am fortunate to be able to dedicate some time each day to reading blogs and technical articles to help stay up to date although I also spend my fair share of time in firefighting mode. The traditional DBA element probably takes up less than 1 day a month partly due to the small size of the estate but also because I've been effective (backslap for myself here!) in automating many of the tasks.
Is my job really a Database Administrator role? I don't think so and in truth it wasn't from the outset but this hasn't been a bad thing. I enjoy the variety of being involved in the different aspects of SQL Server and feel it makes me a much more effective professional and I imagine that this is the case for many other fellow SQL Server pros. However, I've encouraged my company to not advertise the role under this job description as I believe it may attract candidates with unrealistic expectations.
As for me, I'm not sure what my next role has in store but I hope it affords me the time to participate in future T-SQL Tuesdays!!
The task as laid out in the invitation suggested to talk through your day on the 11th or 12th July which just so happened to be the day I resigned from my current role. Writing down a handover list was an interesting task in itself as it gave me the opportunity to put down in words what the key parts of my job were and what skills gap would be left. I have to say, I was surprised (and pleased) that the number of tasks on the list that required significant handover to another collegue were minimal as I have been very diligent in ensuring that I was not a Single Point of Failure in my organisation. As such, I have written plenty of documentation and made extensive use of Source Control and Task Tracking systems to ensure that even if people do not know what I've done, there is a paper trail to explain it.
What was apparent was the varying skills I employ in my day to day, many of which are not even related directly to SQL Server. Much of my day is spent in project meetings, planning or analysing roadmaps and although the applications typically have a database backend, its not the focus of my attention. I am fortunate to be able to dedicate some time each day to reading blogs and technical articles to help stay up to date although I also spend my fair share of time in firefighting mode. The traditional DBA element probably takes up less than 1 day a month partly due to the small size of the estate but also because I've been effective (backslap for myself here!) in automating many of the tasks.
Is my job really a Database Administrator role? I don't think so and in truth it wasn't from the outset but this hasn't been a bad thing. I enjoy the variety of being involved in the different aspects of SQL Server and feel it makes me a much more effective professional and I imagine that this is the case for many other fellow SQL Server pros. However, I've encouraged my company to not advertise the role under this job description as I believe it may attract candidates with unrealistic expectations.
As for me, I'm not sure what my next role has in store but I hope it affords me the time to participate in future T-SQL Tuesdays!!
Tuesday, 1 May 2012
T-SQL: Change Schema of User Defined Type
I've been working with one of our developers to try and rationalise some database objects into some sensible schemas using the ALTER SCHEMA syntax:
http://msdn.microsoft.com/en-us/library/ms173423.aspx
Just out of interest, is it me or is this syntax for changing an objects schema a bit strange? Are you altering the Schema or the Object? Anyhow, I digress...
In our example, we have several User Defined Types which require transfer. Here is some sample code illustrating the problem:
This gives the rather unhelpful error:
I checked the documentation and there isn't anything that suggests types should be treated any differently so I was stumped. Fortunately, I managed to unearth this post which provides a workaround to the problem.
I'm not sure why this is not documented in Books Online (or at least nowhere I can see). One to keep an eye out for.
http://msdn.microsoft.com/en-us/library/ms173423.aspx
Just out of interest, is it me or is this syntax for changing an objects schema a bit strange? Are you altering the Schema or the Object? Anyhow, I digress...
In our example, we have several User Defined Types which require transfer. Here is some sample code illustrating the problem:
CREATE SCHEMA NewSchema
GOCREATE SCHEMA OldSchema
GOCREATE TYPE OldSchema.MyUDT FROM VARCHAR(20);GOALTER SCHEMA NewSchema TRANSFER OldSchema.MyUDT
GO
This gives the rather unhelpful error:
Cannot find the object 'MyUDT', because it does not exist or you do not have permission.I checked the documentation and there isn't anything that suggests types should be treated any differently so I was stumped. Fortunately, I managed to unearth this post which provides a workaround to the problem.
ALTER SCHEMA NewSchema TRANSFER type::OldSchema.MyUDT
GO
I'm not sure why this is not documented in Books Online (or at least nowhere I can see). One to keep an eye out for.
Wednesday, 15 February 2012
T-SQL: Get Last Day of Month
One of my early blog posts highlighted how to get the first day of the current month. Well, another common task is get to the last day of a month and i'm (reasonably) pleased to see that SQL Server 2012 has an inbuilt function to achieve this.
In versions previous to SQL2012, this problem can be solved by running the following:
However, we can now just use the inbuilt function EOMONTH which should make coding easier to read.
You can also specify an offset to the function which will allow you to look at months x number of months from your inputdate which I can certainly see being useful.
Note how the return type is a DATE and not a DATETIME. Interestingly, Books Online suggests that the return type is "start_date or datetime2(7)" although my tests suggest it always returns DATE.
In versions previous to SQL2012, this problem can be solved by running the following:
DECLARE @InputDate DATE = GETDATE() SELECT DATEADD(D, -1, DATEADD(M,DATEDIFF(M,0,@InputDate)+1,0))
However, we can now just use the inbuilt function EOMONTH which should make coding easier to read.
DECLARE @InputDate DATE = GETDATE()
SELECT EOMONTH(@InputDate)
-- 2012-02-29
You can also specify an offset to the function which will allow you to look at months x number of months from your inputdate which I can certainly see being useful.
DECLARE @InputDate DATE = GETDATE()
SELECT EOMONTH(@InputDate, 4)
-- 2012-06-30Note how the return type is a DATE and not a DATETIME. Interestingly, Books Online suggests that the return type is "start_date or datetime2(7)" although my tests suggest it always returns DATE.
Thursday, 9 February 2012
T-SQL: INSERT with XML shredding is very slow
Back in 2010, I came across a performance bug with SQL2008 SP1. When shredding XML using the nodes query, the performance is fine with a SELECT but when you want to INSERT the data to a table/temptable/tablevariable the performance becomes very poor.
The query I was having problems with was something like this (Thanks for the sample data wBob!):
I raised this with MS via Connect (#562092) and went on to implement my own workaround using the following CLR shredding function:
This served me well and solved the performance issue and all was fine. Until now.
The thing is, this method doesn't handle decoding of escape characters in XML, so any &s that exist in the XML string being shredded will be returned as &:amp. Not ideal. My first thought was to just implement a decoding function within the CLR routine but the main candidates use System.Web which is not available within SQL Server. I eventually stumbled upon this post from Jonathan Keyahias which provided a sql safe Encoding implementation and I was going to use this as a basis for writing my own decoding function. While waiting the 20mins for Visual Studio 2008 to open, it occured to me to revisit the Connect case and fortunately, there were a number of workarounds there, and a combination of the solutions the most effective.
The above simple modification to my SQL INSERT statement and performance was acceptable and more importantly, the decoding of the escaped characters was fine. Saved me a lot of work.
The query I was having problems with was something like this (Thanks for the sample data wBob!):
DECLARE @xml XML; -- Spin up some test data WITH cte AS ( SELECT 65 x UNION ALL SELECT x + 1 FROM cte WHERE x < 90 ) SELECT @xml = (
SELECT CHAR( a.x ) + ' & co.' AS "name"
a.x AS "value"
'FIELD' AS "paramdata/field" FROM cte a CROSS JOIN cte b CROSS JOIN cte c
FOR XML PATH('root'), TYPE
) DECLARE @ConfigData TABLE (ID INT, Name NVARCHAR(255), Value NVARCHAR(255), ParamData XML)INSERT INTO @ConfigData (ID, Name , Value, ParamData) SELECT 1,
tbl.cols.value('name[1]', 'varchar(1000)'),
tbl.cols.value('value[1]', 'varchar(1000)'),
tbl.cols.query('./paramdata[1]')FROM @XML.nodes('//root') AS tbl(cols) GO
I raised this with MS via Connect (#562092) and went on to implement my own workaround using the following CLR shredding function:
public partial class UserDefinedFunctions
{
[SqlFunction(FillRowMethodName = "tvf_clr_FillParameterData",
TableDefinition = "Name nvarchar(255), Value nvarchar(255), ParamData nvarchar(255)")]
public static IEnumerable tvf_clr_ParameterDataShredder(SqlXml parameterData)
{
XmlDocument document = new XmlDocument();
document.LoadXml(parameterData.Value);
return document.SelectNodes("//parameter");
}
public static void tvf_clr_FillParameterData(object row, out string outName, out string outValue, out string outParamData)
{
XmlNode document = (XmlNode)row;
outName = document.SelectSingleNode("name").InnerXml;
outValue = document.SelectSingleNode("value").InnerXml;
outParamData = null;
if (document.SelectSingleNode("paramdata") != null)
outParamData = document.SelectSingleNode("paramdata").OuterXml;
}
};
This served me well and solved the performance issue and all was fine. Until now.
The thing is, this method doesn't handle decoding of escape characters in XML, so any &s that exist in the XML string being shredded will be returned as &:amp. Not ideal. My first thought was to just implement a decoding function within the CLR routine but the main candidates use System.Web which is not available within SQL Server. I eventually stumbled upon this post from Jonathan Keyahias which provided a sql safe Encoding implementation and I was going to use this as a basis for writing my own decoding function. While waiting the 20mins for Visual Studio 2008 to open, it occured to me to revisit the Connect case and fortunately, there were a number of workarounds there, and a combination of the solutions the most effective.
INSERT INTO @ConfigData (ID, Name , Value, ParamData)SELECT 1,
tbl.cols.value('(name/text())[1]', 'nvarchar(255)'),
tbl.cols.value('(value/text())[1]', 'nvarchar(255)'),
tbl.cols.query('./paramdata[1]') FROM @xml.nodes('//root') AS tbl(cols) OPTION ( OPTIMIZE FOR ( @xml = NULL ) )The above simple modification to my SQL INSERT statement and performance was acceptable and more importantly, the decoding of the escaped characters was fine. Saved me a lot of work.
Thursday, 2 February 2012
T-SQL: SQL2012 Code Snippets
I've never really bought into the idea of object templates in SQL Server Management Studio and in my experience, not many other database professionals have either!
Just recently however, I've been getting a increasingly frustrated at the non-standard development pattern of database objects and (just as importantly) the lack of documentation for procedures and functions. I've written in the past about using Extended Properties to help version your database and this could easily be extended to document objects too. However, in a previous role I picked up quite a nice habit of adding documentation headers to each procedure and function which gives some basic information to anyone looking at the procedure to give them a headstart in debugging/understanding. A heading may look like this:
Encouraging developers to do this in practice is a real problem and this is where code snippets can come in. There are numerous default snippets available in SQL2012 management studio and you can access them by hitting CTRL-K, CTRL-X and the tabbing to the appropriate snippet:

Here you can see there are already a few default stored procedure snippets including a "create a simple stored procedure" snippet. You can create/add new snippets as you see fit but for my purposes, I want to just modify the existing snippets so they include my header as default.
Take a note of the location of the snippets by navigating to Tools/Code Snippets Manager:

You can then find the .snippet file and make the appropriate modifications. Its just an xml file and for my needs I just needed to make the following change:
When I hit the snippet function, I now get the updated template for my stored procedure. Hoepfully, this will encourage the devs to follow the standards.
Just recently however, I've been getting a increasingly frustrated at the non-standard development pattern of database objects and (just as importantly) the lack of documentation for procedures and functions. I've written in the past about using Extended Properties to help version your database and this could easily be extended to document objects too. However, in a previous role I picked up quite a nice habit of adding documentation headers to each procedure and function which gives some basic information to anyone looking at the procedure to give them a headstart in debugging/understanding. A heading may look like this:
/*
created by: Richard Brown
date created: 02/02/2012
description: this procedure just returns information about customers
debug:
declare @custid = 1
exec dbo.getcustomers @custid
*/
Encouraging developers to do this in practice is a real problem and this is where code snippets can come in. There are numerous default snippets available in SQL2012 management studio and you can access them by hitting CTRL-K, CTRL-X and the tabbing to the appropriate snippet:

Here you can see there are already a few default stored procedure snippets including a "create a simple stored procedure" snippet. You can create/add new snippets as you see fit but for my purposes, I want to just modify the existing snippets so they include my header as default.
Take a note of the location of the snippets by navigating to Tools/Code Snippets Manager:
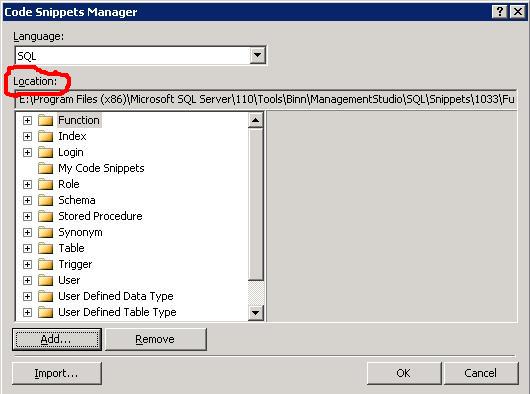
You can then find the .snippet file and make the appropriate modifications. Its just an xml file and for my needs I just needed to make the following change:
<Code Language="SQL">
<![CDATA[
/*
created by:
date created:
description:
debug:
*/
CREATE PROCEDURE $SchemaName$.$storedprocname$
@$Param1$ $datatype1$ = $DefValue1$,
@$Param2$ $datatype2$
AS
SELECT @$Param1$,@$Param2$
RETURN 0 $end$]]>
</Code>
When I hit the snippet function, I now get the updated template for my stored procedure. Hoepfully, this will encourage the devs to follow the standards.
Tuesday, 31 January 2012
Admin: Bulkadmin vs ADMINISTER BULK OPERATIONS
I had an application thrust upon me recently which required the user executing it to have permissions to use the BULK INSERT command in T-SQL. I was aware of the server role bulkadmin which would have been a nice sledgehammer approach to crack this nut, but I was hoping for something a little more refined. Unfortunately, the only thing I came up with was the ADMINISTER BULK OPERATIONS command which would grant this privilege without having the server role membership but I was curious as to what the difference between the 2 was.
As far as I can tell, there is no difference between the 2 operations and both seem to achieve the same thing. From this I assume that bulkadmin is just a wrapper around the ADMINISTER feature although I'd be interested in knowing (as I couldn't find out) if there are other permissions the server role gives you.
Lets look at the example (running on SQL2008 SP2)


So lets see what happens with the server role:

So it seems that the bulkadmin server role doesn't offer any "admin" from a security point of view which begs the question, just why would you add a user to this role rather than just explicity grant them the permission through the GRANT statement (or vice versa)?
As far as I can tell, there is no difference between the 2 operations and both seem to achieve the same thing. From this I assume that bulkadmin is just a wrapper around the ADMINISTER feature although I'd be interested in knowing (as I couldn't find out) if there are other permissions the server role gives you.
Lets look at the example (running on SQL2008 SP2)
-- create some test loginsCREATE LOGIN [DOMAIN\user1] FROM WINDOWS
GOCREATE LOGIN [DOMAIN\user2] FROM WINDOWS
GO-- lets impersonate a userEXECUTE AS LOGIN = 'BARRHIBB\user1'GO-- and check the server permissions SELECT * FROM sys.server_permissions
GOSELECT * FROM fn_my_permissions(NULL,'SERVER')GO -- does the user have bulk op permissions? SELECT has_perms_by_name(NULL, NULL, 'ADMINISTER BULK OPERATIONS');GO
-- lets go back to being a superuser REVERT
GOUSE MASTERGO-- how about if we just grant administer bulk operations to the user? GRANT ADMINISTER BULK OPERATIONS TO [DOMAIN\user1]
GO-- lets impersonate that userEXECUTE AS LOGIN = 'DOMAIN\user1' GO -- and check the server permissionsSELECT * FROM sys.server_permissions
GOSELECT * FROM fn_my_permissions(NULL,'SERVER')GO-- does the user have bulk op permissions?SELECT has_perms_by_name(NULL, NULL, 'ADMINISTER BULK OPERATIONS'); GO
-- can the user grant other users to be bulky people? GRANT ADMINISTER BULK OPERATIONS TO [DOMAIN\user2]
GOMsg 4613, Level 16, State 1, Line 2
Grantor does not have GRANT permission.So lets see what happens with the server role:
REVERT-- remove the users permissions REVOKE ADMINISTER BULK OPERATIONS TO [DOMAIN\user1]
GO -- now add the user to the bulk admin role and check permissions againEXEC MASTER..sp_addsrvrolemember @loginame = N'DOMAIN\user1', @rolename = N'bulkadmin'GO -- lets impersonate that userEXECUTE AS LOGIN = 'DOMAIN\user1' GO -- and check the server permissions SELECT * FROM sys.server_permissions
GOSELECT * FROM fn_my_permissions(NULL,'SERVER') GO-- does the user have bulk op permissions?SELECT has_perms_by_name(NULL, NULL, 'ADMINISTER BULK OPERATIONS'); GO
NB: The main difference here is that the permission has not been explicitly granted but it is an effective permission.-- perhaps with the server role the user grant other users to be bulky people? GRANT ADMINISTER BULK OPERATIONS TO [DOMAIN\user2]
GOMsg 4613, Level 16, State 1, Line 2
Grantor does not have GRANT permission.So it seems that the bulkadmin server role doesn't offer any "admin" from a security point of view which begs the question, just why would you add a user to this role rather than just explicity grant them the permission through the GRANT statement (or vice versa)?
Wednesday, 25 January 2012
Visual Studio: Change default browser
When debugging web apps in Visual Studio, the browser it throws up is typically your default browser. Makes sense I guess. However, once you have many browsers on your machine you may wish to change this.
This is the scenario I cam up against the other day and thanks to this article, I managed to do find a way.
Essentially, you need to right click on an ASP.NET (.aspx) page in your project, right click and select "Browse With..." and change the default browser.


This is the scenario I cam up against the other day and thanks to this article, I managed to do find a way.
Essentially, you need to right click on an ASP.NET (.aspx) page in your project, right click and select "Browse With..." and change the default browser.


NB: if you are developing an MVC with Razor, I found you had to just add an .aspx file to the project to achieve this goal then remove it.
Friday, 20 January 2012
T-SQL: Find missing gaps in data
I recently had solve a problem of finding missing values in a data series and at the same time, came across this article on the new Analytic Functions in SQL2012.
It turns out that there is a new function which can simplify my solution although as the problem is on a SQL2008 database, I won't be able to implement it. Still, another piece of the jigsaw.
Here, I'll present queries for each version:
And how about the all important question of performance? Well, here is a screenshot of the execution plans for the 2 queries where you can see the 2012 implementation does outperform its 2008 counterpart by a ratio of about 3:1.

It turns out that there is a new function which can simplify my solution although as the problem is on a SQL2008 database, I won't be able to implement it. Still, another piece of the jigsaw.
Here, I'll present queries for each version:
USE TempDB
GO -- setup the table CREATE TABLE [dbo].[HoleyTable](
[Date] [datetime] NOT NULL,
[Country] [char](3) NOT NULL,
[Val] [decimal](22, 10) NULL
) ON [PRIMARY]
GO -- and some sample dataINSERT INTO dbo.HoleyTable (Date, Country, Val) VALUES ('20100131','GBP', 40) INSERT INTO dbo.HoleyTable (Date, Country, Val) VALUES ('20100331','GBP', 30) INSERT INTO dbo.HoleyTable (Date, Country, Val) VALUES ('20100531','GBP', 20)INSERT INTO dbo.HoleyTable (Date, Country, Val) VALUES ('20101031','GBP', 50) INSERT INTO dbo.HoleyTable (Date, Country, Val) VALUES ('20101231','GBP', 55) INSERT INTO dbo.HoleyTable (Date, Country, Val) VALUES ('20100228','USD', 20)INSERT INTO dbo.HoleyTable (Date, Country, Val) VALUES ('20100331','USD', 10)INSERT INTO dbo.HoleyTable (Date, Country, Val) VALUES ('20100430','USD', 15) INSERT INTO dbo.HoleyTable (Date, Country, Val) VALUES ('20100630','USD', 25)INSERT INTO dbo.HoleyTable (Date, Country, Val) VALUES ('20100731','USD', 55) INSERT INTO dbo.HoleyTable (Date, Country, Val) VALUES ('20101130','USD', 30) GO -- SQL2008WITH RankedData AS( SELECT *, ROW_NUMBER() OVER (PARTITION BY Country ORDER BY Date) AS rn FROM dbo.HoleyTable ) SELECT a.Country,
b.Date AS StartOfGap,
a.Date AS EndOfGap,
DATEDIFF(m, b.date, a.date)-1 AS missingdatapoints FROM RankedData a
INNER JOIN RankedData b
ON a.rn = b.rn + 1
AND a.Country = b.Country WHERE DATEDIFF(m, b.date, a.date) > 1; GO-- SQL2012WITH PeekAtData AS(SELECT *,
curr = date,
nxt = LEAD(Date, 1, NULL) OVER (PARTITION BY Country ORDER BY date)FROM dbo.HoleyTable )SELECT Country,
curr AS StartOfGap,
nxt AS EndOfGap,
DATEDIFF(m, curr, nxt) -1 AS MissingDatapoints FROM PeekAtData pWHERE DATEDIFF(m, curr, nxt) > 1
GO --tidy upDROP TABLE dbo.HoleyTableGO
And how about the all important question of performance? Well, here is a screenshot of the execution plans for the 2 queries where you can see the 2012 implementation does outperform its 2008 counterpart by a ratio of about 3:1.

Monday, 16 January 2012
What is the RIGHT technology?
One of things I strongly believe in is using the right technology for solving the right problem. You can often find (understandably) that IT professionals look for solutions using technologies they understand best which can lead to inappropriate decsions being taken. "When all you have is a hammer....".
However, just how do you define the right technology?
 An analogy. Whats the best way of buying music? Is it online or in HMV (other retail outlets are available)? Now, for price and convenience then online is pretty tough to beat. But what if you don't have a computer or don't know how to use one? There may be a premium associated with buying in the high street but its still the best understood method there is - everyone knows how to buy from a shop.
An analogy. Whats the best way of buying music? Is it online or in HMV (other retail outlets are available)? Now, for price and convenience then online is pretty tough to beat. But what if you don't have a computer or don't know how to use one? There may be a premium associated with buying in the high street but its still the best understood method there is - everyone knows how to buy from a shop.
I've been involved with a particular application written entirely on SQL Server technologies and its an impressive implementation. Its fast and reliable and for someone familiar with the technology entirely supportable. However, its not me that has to use it. The "customer" has limited technology skills and yet is tasked with driving the application with recurring difficulty and as a consequence, there is a feeling that the application is not robust. The fact is, that the application is entirely robust, but is not built for a technology-light person to use.
 Previous to the SQL implementation, there was an Excel equivalent which was less robust and performant. However, the users fully understood how to work it and were much more comfortable with it even at the cost of longer runtime. Asked to use its Excel predecessor, I would have probably claimed it not robust as a result of not being comfortable using that technology. Same issue, different technology.
Previous to the SQL implementation, there was an Excel equivalent which was less robust and performant. However, the users fully understood how to work it and were much more comfortable with it even at the cost of longer runtime. Asked to use its Excel predecessor, I would have probably claimed it not robust as a result of not being comfortable using that technology. Same issue, different technology.
We need to make the right technology choices and this doesn't just mean what is the best technology for the job. First and foremost, applications need to be fit for purpose and usable by the customer even if thats at the expense of the most elegant technology solution. If customers have no experience or understanding of a particular technology, then we shouldn't be building solutions that require that skillset. Simple.
However, just how do you define the right technology?
I've been involved with a particular application written entirely on SQL Server technologies and its an impressive implementation. Its fast and reliable and for someone familiar with the technology entirely supportable. However, its not me that has to use it. The "customer" has limited technology skills and yet is tasked with driving the application with recurring difficulty and as a consequence, there is a feeling that the application is not robust. The fact is, that the application is entirely robust, but is not built for a technology-light person to use.

We need to make the right technology choices and this doesn't just mean what is the best technology for the job. First and foremost, applications need to be fit for purpose and usable by the customer even if thats at the expense of the most elegant technology solution. If customers have no experience or understanding of a particular technology, then we shouldn't be building solutions that require that skillset. Simple.
Wednesday, 11 January 2012
Admin: Start and Stop Local Instance of SQL Server
As a database professional, i'm accustomed to having a local sql server instance installed. However, it seems that SQL Server (typically Express) is finding its way onto more and more desktops, often unused and unknown to the user!! With the web browser FireFox taking up almost half your memory, you don't want any other applications taking your valuable resources.
I recommend changing the service settings of your SQL services to manual and only turning them on when you are actually going to use them. If you're using a shared database server, you may find that even as a SQL developer you may not use your local instance as often as you might have thought.
I have created 2 simple batch files on my desktop which I can use for stopping and starting my local SQL services meaning its a mere double click away to get your instance available.
StartSQLServices.bat
NET START mssqlserver
NET START sqlserveragent
NET START ReportServer
NET START msdtsserver100
StopSQLServices.bat
NET STOP mssqlserver
NET STOP sqlserveragent
NET STOP ReportServer
NET STOP msdtsserver100
* your Service names may vary depending on instance names and SQL version.
I recommend changing the service settings of your SQL services to manual and only turning them on when you are actually going to use them. If you're using a shared database server, you may find that even as a SQL developer you may not use your local instance as often as you might have thought.
I have created 2 simple batch files on my desktop which I can use for stopping and starting my local SQL services meaning its a mere double click away to get your instance available.
StartSQLServices.bat
NET START mssqlserver
NET START sqlserveragent
NET START ReportServer
NET START msdtsserver100
StopSQLServices.bat
NET STOP mssqlserver
NET STOP sqlserveragent
NET STOP ReportServer
NET STOP msdtsserver100
* your Service names may vary depending on instance names and SQL version.
Subscribe to:
Posts (Atom)